A Super short note on IPC protocols
Date : 27 November 2016
Version: 0.5
By: Albert van der Sel
Status: Ready.
Remark: Please refresh the page to see any updates.
1. Introduction:
Different applications may sometimes need to "communicate" with each other, or exchange information.
Such applications may live on the same "machine", or they may be installed on different machines.
It's quite typical of (higer level) applications that they focus on certain functional tasks, or exhibit all sorts
of business functionality. They themselves, are often not involved in interfacing and lower level protocols.
Suppose two applications are indeed on different machines. If they need to exchange information,
then it is obvious that those applications ultimately need to use the services of the transport/network modules, which
are already installed on those machines, just to get the data "on the wire". Ofcourse, all typical network related issues like
addressing, assembling segments, error correction, media-acces etc... is taken care of by such a "network-stack".
So, the the bottom layers are handled then, by the network stack.
However, maybe App1 on Machine1, wants to activate, or call, a certain procedure of App2 on Machine2.
This procedure of App2, may for instance perform a very specific task, which only that procedure can
perform on Machine2.
A solution might be that App1 uses a "proxy", or a stub, which is a library or repository of all callable functions
of App2, but not the full code itself. Then, when needed, App1 selects the function to call, and the local stub
wraps it up and passes it to the local transport/network layer in order that it will reach App2 on the other machine.
Or as another scenario, maybe App1 and App2 need to pass along messages of data, or a temporary stream of data,
and a mechanism is in place that it just "looks" as if they simply perform Filesystem IO, while in reality
this IPC mechanism (like a named pipe) wraps it, and passes it to the transport/network layer.
This "middleware" between the Application and Transport/networks stack, is often called
an "Inter Process Communication" (IPC) protocol or mechanism.
A very high-level picture of this can be seen in figure 1 below:
Figure 1: High-level overview "Application-IPC-Network" stack.
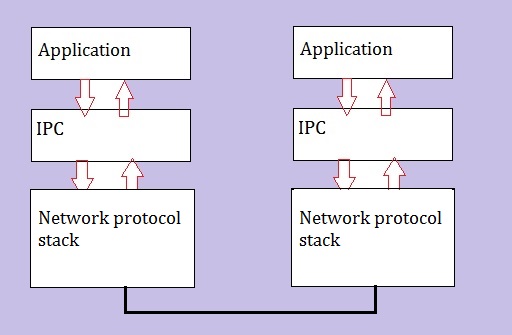
Applications (or distributed modules of those app's) may communicate using a variety of IPC's.
Some well-known IPC's are "RPC", "shared memory", "named pipes", "sockets", and a couple more of such IPC's.
Java applications may use some specific IPC's in the Java architecture, like RMI (Remote Method Invokation),
which is quite similar to RPC. In another note, I like to go into some main Java specific IPC mechanisms.
For communication between applications, in principle, only one IPC mechanism should suffice.
But for various functions, it's possible that other IPC mechanisms are "called in" too.
Each IPC method has its own specific advantages and certain limitations, so it is not unusual for a single application
to use multiple IPC methods.
Figure 2: Hopefully, a "Reasonable" picture showing some main IPC's, with respect to possible dependencies:
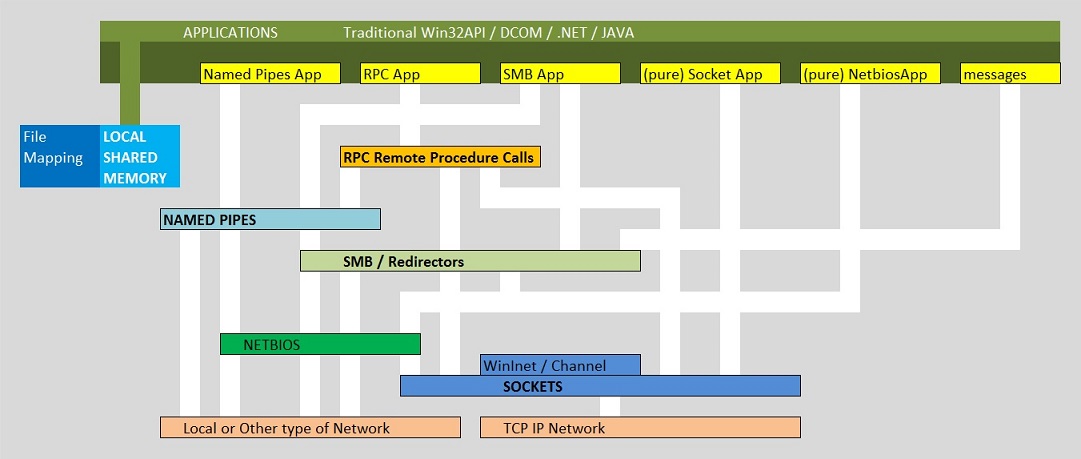
By the way, no picture showing IPC's, can be perfect: it will never make everybody happy.
One cause of this might be, if one uses a top-down perspective, and is very strickt on the relative
positions of IPC's. However, the picture above only tries to show which mechanism might depend (or use) functions
of other mechanisms.
-Remember that, in principle, an Application should use one IPC method to communicate with another remote Application.
-However, sometimes, for various functions, often multiple IPC's are selected.
-And it is also true that a certain IPC, may use the exposed "methods" of another IPC, for certain functionality.
You may also wonder how providers/libraries as ODBC and OLEDB etc.. would fit in such a picture as shown in figure 2.
These providers are pretty much "high-level", and the appendices will show some common examples.
Maybe it's not a bad idea to discuss a few of those IPC's.
2. Named Pipes:
This one is often used in situations where two processes are on different machines.
The "conceptual" idea is easy to visualize: picture a client process and a serverprocess.
Next, visualize a "tube" between those processes, which they use to exchange information.
Ofcourse, the above is a bit too simply put. However, the protocol stems from a long time back, and
two "modes" of usage could be distinguished: "byte mode" and "message mode".
Especially the "byte mode" gives you a sort of feel for a "pipeline" where bytes are streamed from the one process
to the other (ofcourse, with buffering when needed).
It really looks like a unix pipe, where the output from one program is fed into a second program.
Pipes or "named pipes" (if they really have a identifier as a "name"), absolutely looks like filesystem IO.
In fact, when a pipe is instantiated, a "handle" is declared and bound to the pipe.
As you might know, "handles" are the mechanism by which a file is accessed.
Further, when the pipe is used, we actually have functions as "ReadFile()" and "WriteFile()" active, in order
to send and receive data.
You might see it as an (OSI) session layer protocol (layer 5), and it just uses the services of an underlying network protocol.
Yes indeed. Named pipes can just float on almost any networkprotocol.
In Microsoft systems, it is a fact the it may use modules of the "redirector" services in the Operating System, which
enhances the view that it simply resembles filesystem IO.
You can also see that in the "named pipe" identifier, which is an UNC path like "\\Servername\PIPE\MyPipe",
or, if you have some server process on your system which uses named pipes, you can find a name like "\\.\pipe\pipename"
on your system, for example in the Registry (note: "\\." is a synonym for the local system).
3. Shared Memory:
Some applications use "shared memory" for exchange of information.
It is true that some architects and developers do not view it as a true IPC mechanism.
A characteristic however, is that the applications reside on the same system and Operating system.
While other IPC's more often use networks or remote communications, the "shared memory" works local.
I immediately haste myself to say that indeed "distributed" memories across systems do exist.
But in the mainstream of commodity applications, the use of shared memory is a local business (local to the machine).
A good example are the typical Database engines. At startup, such an engine reserves an area of shared memory,
and all sorts of background processes (belonging to that Database engine), and server processes can access parts
of the shared memory. This way, exchange of information can be realized (e.g. rows of some table).
The systemcall interface (or API) of the OS, usually provides functions to reserve and release "shared memory".
Typically, once in place, the processes can read and write in those memory segments without calling operating system functions.
This is neccessary, while otherwise "access violations" by the OS would be signalled al the time.
Ofcourse some sort of synchronization mechanism must be in place, otherwise the whole thing becomes a "zoo",
and strange things will happen.
Often (but not exclusively) "mutexes" will handle the synchronizations.
It's short for "mutual exclusion" object. A mutex is a program object that allows multiple program threads to share
the same resource, but not simultaneously.
Other "signals" (or flags) that are used to "signal" that some resource is in use, are "semaphores",
and "latches" (whereby the latter is a general term for locks on resource objects).
4. TCP Sockets:
I like to distinguish only 2 (on what I think) are really different ones, namely
"domain sockets" and "network sockets".
Domain socket:
A "domain socket" is an IPC method by which processes, usually on the same host, can communicate.
Such a socket again looks like a sort of filesystem IO, and is known by a pathname.
So, a "pipe" and a domain socket on a unix/linux system, have quite a few similarities tin common.
Network socket:
A "network socket" is relatively easy to understand. A service, addressable or reachable by a network socket,
is then identified by an IP address and port.
These sockets can be used with local- and remote communications.
When talking about IPC in networks, usually, folks mean TCP- or "network sockets".
So, here I only like to say a few words on network-, or TCP sockets.
Figure 3:
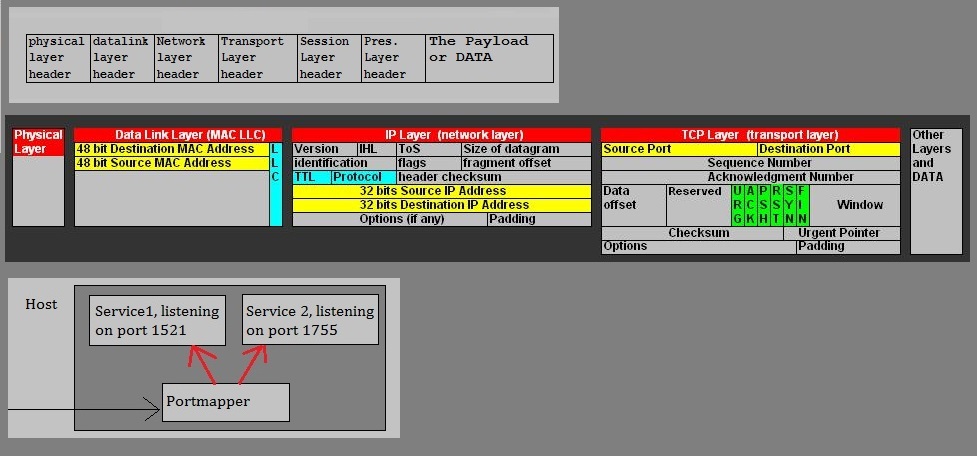
The figure above, shows three parts. Please take notic of the middle picture.
Here we see the IP header and TCP header of an IP packet in a Local Aera Network.
The IP header is mainly occupied with "addressing" business (source- and destination IP address).
Now look at the TCP header. Here we see the source- and destination ports as fields in that header.
You may have identified a machine in the network by it's address, but what if multiple "server" services
are running on that machine. How to identify such service? It's done by it's "port". And in the figure,
it would then be the "destination port" (like for example 1521).
In fact, the string "IP address:Port" completely identifies a service on a remote machine.
For example, we could have the string "202.100.100.43:1521", which identifies a service on the machine
using the IP address 202.100.100.43, where that service "listens" for connections to port "1521".
Usually, server services use fixed ports (where they listen on), like for example 1521.
The clients of those server services, often use dynamically choosen ports, as long as such port
is not already occupied by some other client process (on some specific client machine).
A string as "IP address:Port", is often called a "network socket". Such sockets functions as
the connection points between client- and server processes (usually on different machines).
On the server machine, a generically named process "the portmapper", will dispatch the recieved TCP segments,
to the services which are listening on their own port.
On some Operating systems (some unixes), such a process is indeed named (like something that looks) like "portmapper".
But on most other platforms, you do not see something like that in a process listing.
5. Remote Procedure Call or RPC:
If you work with Windows, I can tell you that it "a lot of it, runs completely on RPC.
If RPC is used between modules within the same Operating System (machine), then RPC is often renamed to LPC.
LPC is short for "Local Procedure Call".
We will treat RPC here in it's usual context, that is, a program (module, object...) on a certain machine,
want to have a remote program (that is, on another machine), to execute a "procedure".
By the way, since "object oriented programming" (OOP) is practically done everywhere nowadays, such procedures are
often called "methods" which we can associate with a (program) "object".
If a developer creates a OOP "object", he/she also writes code like "member functions", which are defined within that object.
Usually, public and private methods are written, where the public ones can be "called" by an external entity (like another object).
So, suppose we have App1 on Machine1, and App2 on Machine2. A number of important questions immediately arises:
-How does App1 "knows" which methods it can "call" from App2?
-Secondly, how does App2 knows that it must execute that specific method (on request of App1)?
This is all covered by the RPC protocol.
Certain implementations uses a sort of "table" of pointers, which describes how methods can be "called". Sometimes his is called
the "vtable" approach.
It can also be a part of the "Interface Definition" (IDL), which makes it possible how App1 knows how to call "what" on App2.
Let's first study the figure below:
Figure 4:
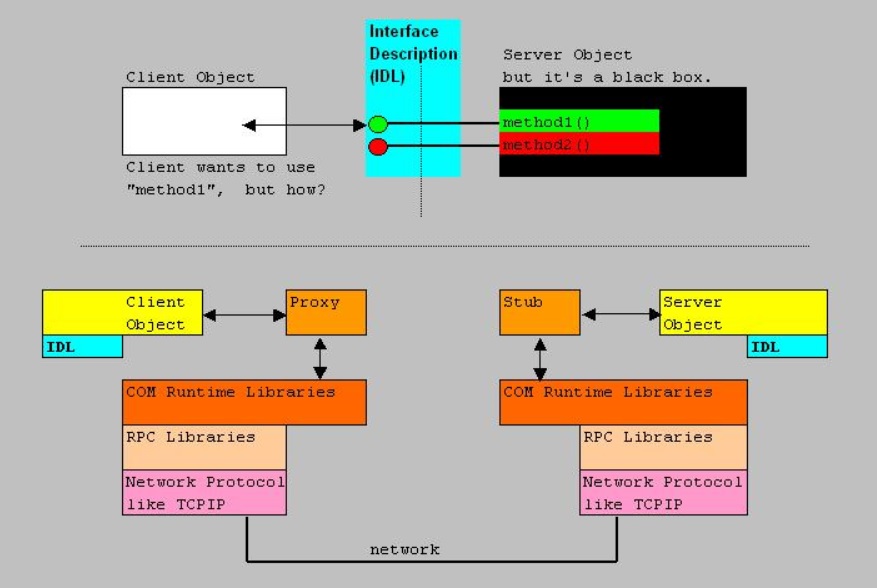
Let's suppose that an IDL, or a sort of vtable, provides App1 with the knowledge what function calls (method calls)
it can ask of App2.
Then App1 selects the correct pointer, the Proxy/Stub marshalles it to the correct format, and wraps it up to a format
which the underlying IPC mechanism can understand, and the stream is handed over to for example the "sockets" interface.
From then on, the usual and regular network technology jumps in. At the server side, the Proxy/Stub acts like a local client,
and the member function is executed by App2.
Note: figure 4 was created with (D)COM applications in mind, which primarily uses RPC as a common IPC.
6. Message passing:
There may exist different perceptions on this.
However, the usual "Message Exchange" interpretation, is, generally, not the same as "Message Passing".
But I must say that the boundary is not always very clear, and indeed, sometime "Exchange" works like "Passing".
I think that I can make this clear...
- Message exchange:
For example, here you may think of transmitting pure XML data, in a SOAP envelope, using http, to a receiver,
where that XML data is parsed and further interpreted. Maybe that XML data was nothing more than a request
to place an order, or a request for stock information, or data that must be stored at the receiver etc..
As another example, you might also think of some MQ (Message Queuing) service, where transmit- and receive queue's
exist at both the sender and receiver, and data messages get transferred when needed.
When the receiver is temporarily unavailble, the messages will stay in the queue, until they can be processed.
- Message Passing:
This is really an IPC mechanism. Most Operating Systems and applications make use of it.
I think that (generally) three main types exist, but we must not view this division to be very "hard":
1. "Events" and nummeric identifiers on/in the same Operating System, and Applications.
In Windows applications, it is heavily used, especially in graphical applications (thus practically all).
In the Windows example, a "message" is simply a numeric code that uniquely corresponds to a particular event.
A mouseclick to minimize a Window, will make that the Operating System sends the corresponding "code" (e.g. for WM_LBUTTONDOWN)
to that particular Window.
So, Message Passing in "Event-driven" applications (on the same system) is very common.
Especially traditional programmers on the Win32 API, can probably just list many of them without consulting any documentation.
2. Calling "methods" (functions) of local or remote objects.
You might say that this looks like "RPC". Yes, but generally, the request is encapsulated in a "message".
So, for example, while it seems completely natural that SOAP on HTTP is used for transmitting data,
it can also be used to request a remote service to execute a procedure.
If the infrastructure at the receiver allows it (like that "endpoints" are defined), the content of the request
in that message will simply lead to the fact that the procedure is executed.
3. MPI Interface.
The message passing interface (MPI) of "C" and some other languages, and some "shells", makes it possible that
send() and receive() functions can be used, with the objective to activate code on a local or even remote object.
The "formal" MPI specification, is quite an elaborate framework.
I think that the descriptions as listed in (1) and (2), are the most common Message Passing models.
In specific situations, or when one likes, or one must use C (and comparable development platforms), or
the infrastructure simply demands it, then (3) is used.
For (2) and (3), often TCP sockets are used as the lower level IPC.
So, I guess that this is about it, for what I like to say on some standard IPC mechanisms.
Some platforms have some specific IPC mechanisms. It's indeed interesting to explore the "Java world"
with respect to IPC. I like to do that in another note.
That's it. Hope you liked it!
Appendices:
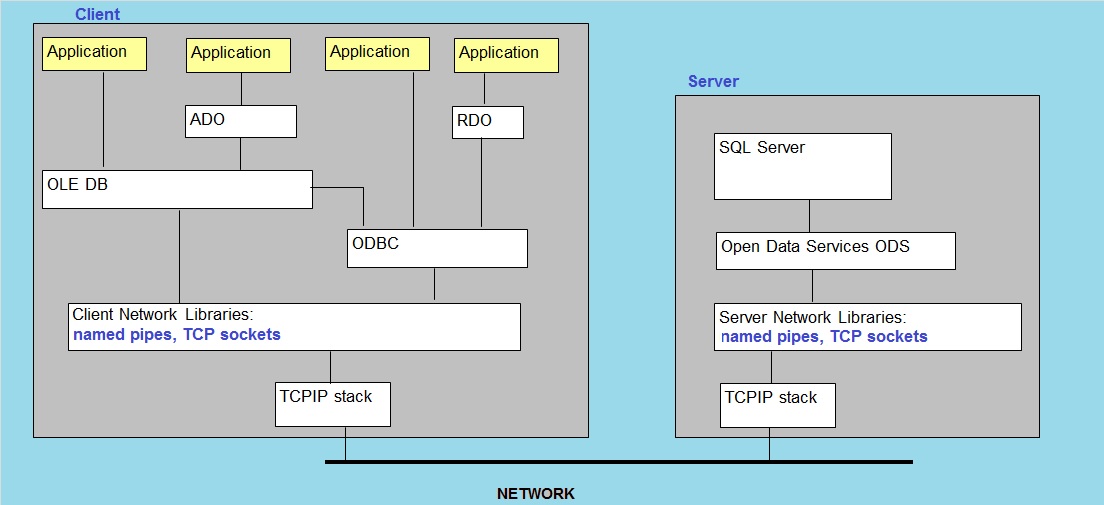
1. Traditional SQL Server "Client/Server" Connection model:
IPC and the traditional SQL client connectivity.